Rails Active Job style guide

What does Active Job do?
Delegates execution of code to a background process
What type of work usually gets done in a job?
- Sending emails
- API calls to 3rd parties
- Report generation
- Data import/export
- Bulk operations
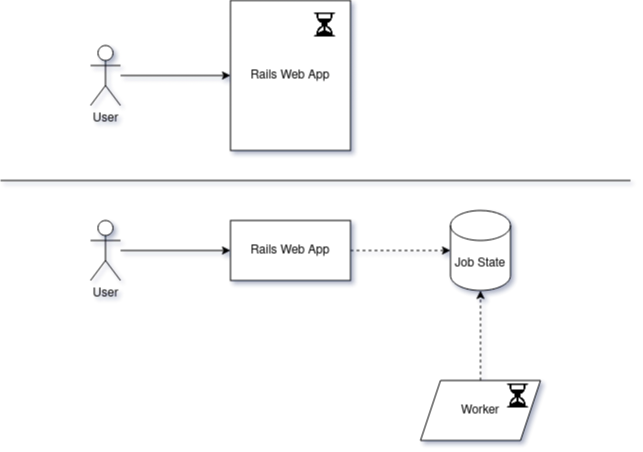
Technology
Active Job is only an abstraction over background jobs...
When you talk about web development with Ruby, you know it's Rails!
When you talk about background jobs with Rails, you know it's Sidekiq!
Sidekiq
https://sidekiq.org/
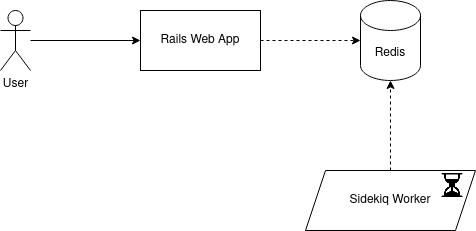
Why Sidekiq won?
Active Maintainer that develops it with a Business Plan!
Redis takes the load off of the main Database
Easy to deploy, encouraged by Heroku
Micro-benchmark optimised
Ruby's ecosystem has a "winner takes all" mentality (see Rails)
And that's a good thing!
You know what you'll have to deal with in every Ruby web app you will ever encounter
And Active Job standardises it in case you need to deviate from the norm
Enterprise?
Do you need it? No!
Convenience for organisations with too much money...
Direct customer support for the developer
Configure
Gemfile
gem 'sidekiq'
config/sidekiq.yml
---
:concurrency: <%= ENV.fetch('SIDEKIQ_CONCURRENCY', '5') %>
:timeout: 25
:verbose: true
:queues:
- critical
- default
- low
config/initializers/sidekiq.rb
Sidekiq.configure_server do |config|
host = ENV.fetch('REDIS_HOST', 'localhost')
port = ENV.fetch('REDIS_PORT', '6379')
protocol = ENV.fetch('REDIS_PROTOCOL', 'redis')
config.redis = { url: "#{protocol}://#{host}:#{port}/0" }
end
Sidekiq.configure_client do |config|
host = ENV.fetch('REDIS_HOST', 'localhost')
port = ENV.fetch('REDIS_PORT', '6379')
protocol = ENV.fetch('REDIS_PROTOCOL', 'redis')
config.redis = { url: "#{protocol}://#{host}:#{port}/0" }
end
config/application.rb
config.active_job.queue_adapter = :sidekiq
Example Job
bundle exec rails generate job Example
class ExampleJob < ApplicationJob
queue_as :default
def perform(*_args)
Rails.logger.info('Hello Job!')
end
end
Run worker
bundle exec sidekiq -C config/sidekiq.yml
A separate process that you need to deploy!
Enqueue it
In your Rails application, or in `rails console` you can:
ExampleJob.perform_later
Logs
Your application logs will say:
Enqueued ExampleJob (Job ID: 33c16d97-0694-4ed0-91fd-6746f9e2f250) to Sidekiq(default)
Your worker logs will say:
jid=123abc INFO: start
jid=123abc INFO: Performing ExampleJob (Job ID: 33c16d97-0694-4ed0-91fd-6746f9e2f250) from Sidekiq(default) enqueued at ...
jid=123abc INFO: Hello Job!
jid=123abc INFO: Performed ExampleJob (Job ID: 33c16d97-0694-4ed0-91fd-6746f9e2f250) from Sidekiq(default) in 330.94ms
Good Practices, not Best Practices!
Good practce no. 1
Use services
class ExampleJob < ApplicationJob
queue_as :default
def perform(*_args)
SomeService.new.call
end
end
# In some other file
class SomeService
def call
Rails.logger.info('Hello Job!')
end
end
Why?
- Keeps jobs small and easy to review
- Easy to reuse and compose functionality by mixing services together
Good practce no. 2
Database transactions are not implicit around `perform`. Use them only when necessary.
class ExampleJob < ApplicationJob
queue_as :default
def perform(*_args)
ApplicationRecord.transaction do
SomeService.new.call
end
end
end
Why does it not do this by default?
- It's generic enough to not to force a dependency on ActiveRecord
- Sometimes you don't want to have transactions around your entire code
- Example: failing an API call with an error should not rollback your API call papertrail
Good practce no. 3
Make your jobs/services Idempotent
Depends on he business logic...
If you run it twice, or 100 times, it should have the same effect/result
Track if you've already sent emails, don't do API calls if you already have the result
Good Practice no. 4
Chain Jobs in the `perform` method.
class ExampleJob1 < ApplicationJob
queue_as :default
def perform(*_args)
result = SomeService.new.call
ExampleJob2.perform_later(result.first)
ExampleJob3.perform_later(result.last)
end
end
Why?
- Easy to follow chains if you have them in the Jobs only, and not deeply nested within services.
- Services can be ran independently without triggering the rest of the chain.
- If you really need the chain to run you can `perform_later`
Sometimes chains get complex
1 -> 2 -> 3 -> 4
|
---> 5 -> 6
|
---> 7
There are no tools to visualise this, you need to document it!
Sometimes chains get crazy
1 -> 3
^
|
2 ---
3 requires both 1 and 2 to finish before proceeding
- Store the results of both 1 and 2 in a database
- Enqueue 3 at the end of both 1 and 2
- Use transactions and check if the result of 3 is done
- Skip one of the enqueued 3s if it's result is ready
Rare in practice, you might never need to do this
Unique Jobs
Only enqueue job 3 if it has not been enqueued yet
This is the convenience that unique jobs give you (part of Enterprise)
But there are FOSS libraries that implement unique jobs as well
https://github.com/mhenrixon/sidekiq-unique-jobs
You still need gatekeep your code for uniqueness with transactions if you really need such guarantees
Good Practice no. 5
Versioned Arguments
class ExampleJob < ApplicationJob
queue_as :default
def perform(*args)
if args['version'] == 1
SomeService.new.call(payload: args['body'])
elsif args['version'] == 2
SomeService.new.call(payload: args['body']['payload'])
else
Rails.logger.error("Unkown version #{args['version']}")
end
end
end
Why?
You don't need to create a new `ExampleJobV2` to handle the same functionality
You don't need to replicate the control logic (if you have any)
Backwards compatible jobs allow you to drain the queue after deploy (zero "downtime" job updates)
Cleanup is easier, testing can use shared examples in the same spec
Good Practice no. 6
RTFM (read this fine manual)
https://github.com/mperham/sidekiq/wiki
https://guides.rubyonrails.org/active_job_basics.html
That's it, that's the good practice... just... just do it.
Good Practice no. 7
Use Sidekiq's builtin mechanisms to make your life easier
But don't force it to do something it's not meant to...
Example: Timeouts and Retries
Timeouts
Keep your jobs small and quick so they have a chance to finish when K8s wants to restart pods
Set a reasonable timeout so you don't keep the worker busy with laggy 3rd party APIs
Heroku used to suggest to set the timeout at 10 seconds and ensure jobs finish within 5 most of the time
5 seconds ought to be enough for everybody!
Retris
Sidekiq has an automatic retry mechanism on error
# | Next retry backoff | Total waiting time
--------------------------------------------
1 | 0d 0h 0m 30s | 0d 0h 0m 30s
2 | 0d 0h 0m 46s | 0d 0h 1m 16s
3 | 0d 0h 1m 16s | 0d 0h 2m 32s
4 | 0d 0h 2m 36s | 0d 0h 5m 8s
5 | 0d 0h 5m 46s | 0d 0h 10m 54s
6 | 0d 0h 12m 10s | 0d 0h 23m 4s
7 | 0d 0h 23m 36s | 0d 0h 46m 40s
8 | 0d 0h 42m 16s | 0d 1h 28m 56s
9 | 0d 1h 10m 46s | 0d 2h 39m 42s
10 | 0d 1h 52m 6s | 0d 4h 31m 48s
... and more until 25 tries
If you need quicker, more frequent retries (60 times, no delay), that's business logic, not Sidekiq
Good Practice no. 8
Log things!
Tail the logs of your rails server and sidekiq worker during development
Use `Rails.logger.debug` as much as you need to not require `binding.pry` (don't log PII)
Use `Rails.logger.info` major steps in your logic (like 3rd party calls)
Use the Job ID to link them!
Web logs:
Enqueued ExampleJob (Job ID: 33c16d97-0694-4ed0-91fd-6746f9e2f250) to Sidekiq(default)
Worker logs:
jid=123abc INFO: start
jid=123abc INFO: Performing ExampleJob (Job ID: 33c16d97-0694-4ed0-91fd-6746f9e2f250) from Sidekiq(default) enqueued at ...
jid=123abc INFO: Hello Job!
jid=123abc INFO: Performed ExampleJob (Job ID: 33c16d97-0694-4ed0-91fd-6746f9e2f250) from Sidekiq(default) in 330.94ms
Good Practice no. 9
Test the flow and the service logic separately
You don't need to execute the services in unit tests:
it 'enqueues ExampleJob2' do
result = [1, 2, 3]
allow_any_instance_of(SomeService).to(
receive(:call).and_return(result)
)
expect(ExampleJob2).to(
receive(:perform_later).with(result).and_return(true)
)
ExampleJob1.perform_now
end
Good Practice no. 10
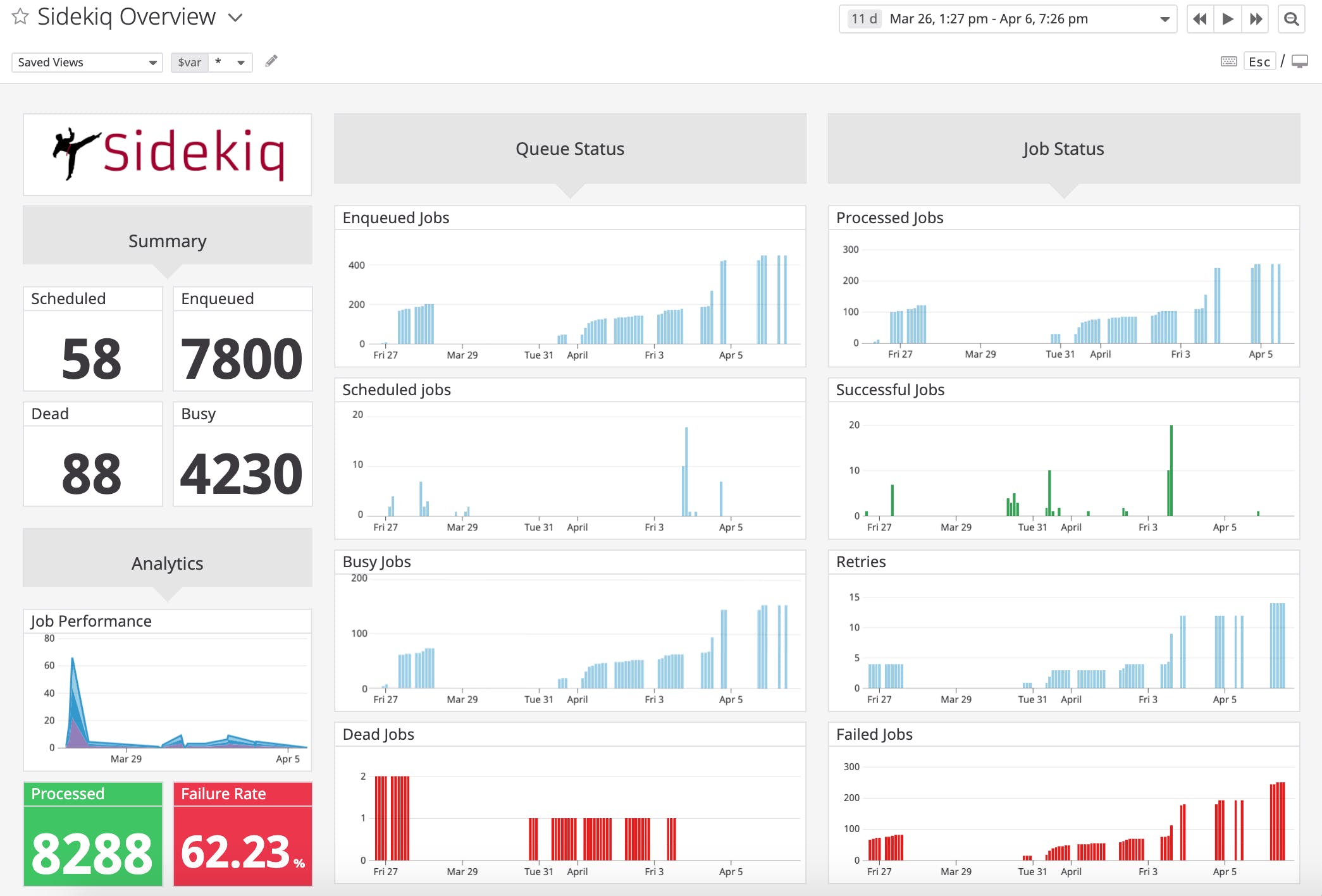
Deploy and use the dahsboard
It's good!
These are just suggestions, not laws!
Use whichever you think fits best.
When in doubt, always use common sense!
Discuss with the team.